Copyright © 2019-2026 幻思创新 Fancinnov® 版权所有
第一章 JetsonNX基础环境搭建
概述
本节教程将会教会你JetsonNX的基础环境搭建,保证各位在之后的学习道路上不再会为环境问题而苦恼
实验平台:FanciSwarm机载电脑无人机 ubuntu-20.04LTS
文件总览
FanciSwarm单目yolo文件包 提取码: jfjq
20.04-yolo
├─ 70-ttyusb.rules
├─ auto_ap.sh
├─ datalink_serial.py
├─ mavcrc.py
├─ mavcrc.pyc
├─ mavlink.py
├─ mavlink.pyc
├─ opencv-4.6.0.zip
├─ opencv_contrib-4.6.0.zip
├─ tensorrtx.zip
├─ torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
├─ vision-release-0.16.zip
├─ yolov5.zip
└─ yolov5_det_trt.py
ROS1安装
说明:① 系统已预装 ROS1,无需重复安装,可直接跳过 ROS1 安装步骤。
② 如何确认系统已安装ROS1:
第一步:打开终端,输入命令:roscore
第二步:查看运行结果,如下图:
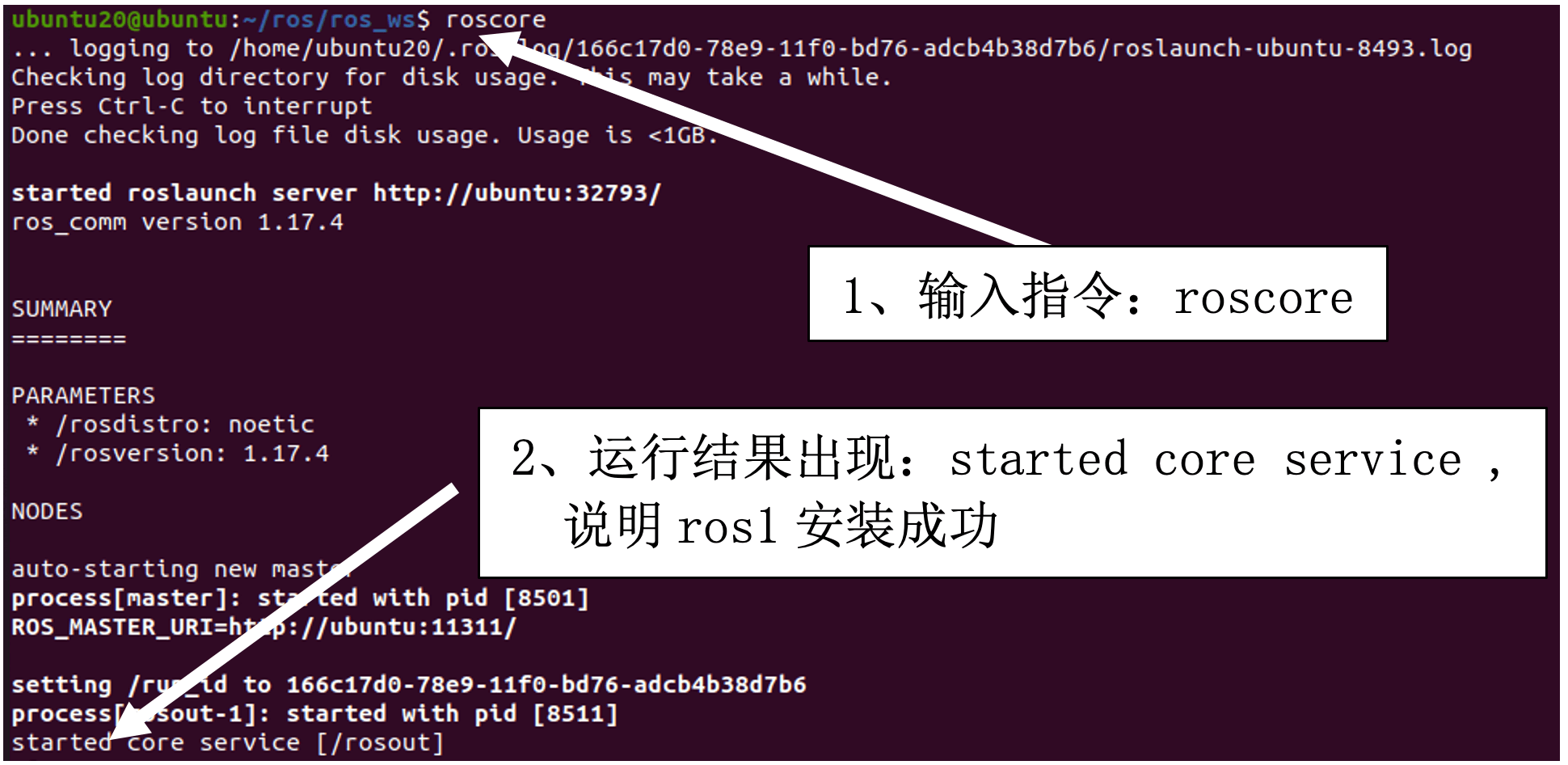
我们使用fishros一键环境配置工具进行ROS1-noetic版本的安装
- 在终端输入下面命令
wget http://fishros.com/install -O fishros && . fishros
- 出现下面打印之后
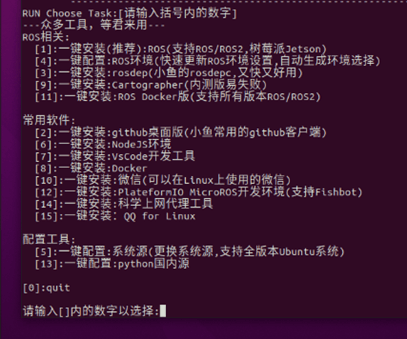
我们首先选择5,系统源的更新

这一步我们选择2

这一步选择1,添加ros源
- 安装ros,我们再次输入下面命令
wget http://fishros.com/install -O fishros && . fishros
- 出现下面打印之后
然后我们输入 1 一键安装 –> 不更换源安装 –> 选择你ubuntu版本对应的ros版本(这里我们选择ROS1的noetic) –> 桌面版进行安装
- 配置rosdep
source ~/.bashrc
sudo apt install python3-rosdep python3-rosinstall python3-rosinstall-generator python3-wstool build-essential
sudo rosdep init
rosdep update
至此ros1已经安装完毕
安装超级终端
超级终端便于同时运行多个程序,可以进行横向纵向分割
sudo apt-get install terminator -y
安装以及配置CUDA
- 添加源
sudo gedit /etc/apt/sources.list.d/nvidia-l4t-apt-source.list
加下面两行进去
deb http://repo.download.nvidia.com/jetson/common r35.4 main
deb http://repo.download.nvidia.com/jetson/t234 r35.4 main
- 更新源
sudo apt upgrade
sudo apt update
- 装jetson包
sudo apt install nvidia-jetpack
- 配置环境变量
gedit ~/.bashrc
下面添加:
export LD_LIBRARY_PATH=/usr/local/cuda/lib64
export PATH=/usr/local/cuda/bin:$PATH
export CUDA_HOME=/usr/local/cuda
- 更新环境变量
source ~/.bashrc
- 复制文件到cuda目录
cd /usr/include && sudo cp cudnn* /usr/local/cuda/include
cd /usr/lib/aarch64-linux-gnu && sudo cp libcudnn* /usr/local/cuda/lib64
- 查看cuda
nvcc -V (出现下述信息代表安装cuda成功)
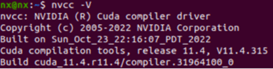
- 安装jtop(便于查询系统情况)
sudo apt install python3-pip
sudo -H pip3 install -U pip
sudo -H pip install jetson-stats
重启之后执行如下指令运行
jtop
安装opencv4.6.0 with cuda以支持GPU加速
下载地址:Release OpenCV 4.6.0 · opencv/opencv
扩展模块:Release 4.6.0 · opencv/opencv_contrib
(如果网不好,这两个依赖库也可以用幻思提供的)
解压放在home路径即可
确定 Jetson Orin NX 的算力为 8.7

cd opencv-4.6.0/
mkdir build && cd build (如果用幻思的库,已经存在build文件夹,只需要cd build)
预编译opencv 4.6.0及其扩展模块 opencv_contrib-4.6.0,生成 Makefiles 文件,如果使用幻思的库,要先将build文件夹下的缓存文件全部删除,并且确保opencv和opencv_contrib都解压到home文件夹后再去执行下面指令
cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local/ \
-D OPENCV_EXTRA_MODULES_PATH=../../opencv_contrib-4.6.0/modules \
-D WITH_CUDA=ON \
-D CUDA_ARCH_BIN=8.7 \
-D CUDA_ARCH_PTX="" \
-D ENABLE_FAST_MATH=ON \
-D CUDA_FAST_MATH=ON \
-D WITH_CUBLAS=ON \
-D WITH_LIBV4L=ON \
-D WITH_GSTREAMER=ON \
-D WITH_GSTREAMER_0_10=OFF \
-D WITH_QT=ON \
-D WITH_OPENGL=ON \
-D CUDA_NVCC_FLAGS="--expt-relaxed-constexpr" \
-D WITH_TBB=ON \
..
其中CMAKE_INSTALL_PREFIX=/usr/local/ 为安装地址,OPENCV_EXTRA_MODULES_PATH=../../opencv_contrib-4.6.0/modules 为扩展模块所在路径,
CUDA_ARCH_BIN=8.7 为 GPU 算力,
编译完成后如下所示
然后make install 编译安装 opencv 4.6.0 及其扩展模块 opencv_contrib-4.6.0,此安装过程较为漫长,请耐心等待。
sudo make install -j8
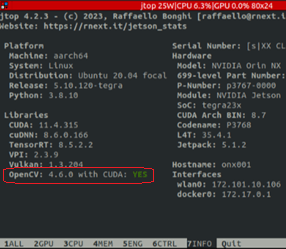
安装完成后用
jtop
查看版本
YOLO-V5配置
sudo pip3 install torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
sudo apt-get install libopenblas-dev
cd vision-release-0.16
export BUILD_VERSION=0.16
python setup.py install --user
cd ..
$ python3
>>> import torch
>>> import torchvision
>>> print(torch.__version__)
>>> print(torchvision.__version__)
以上为检查torch版本信息,如果有证明安装成功。
pip install tqdm
pip install Ipython
pip install seaborn
git clone -b v7.0 https://github.com/ultralytics/yolov5.git
git clone -b yolov5-v7.0 https://github.com/wang-xinyu/tensorrtx.git
如果以上两个工程用git下载,应把幻思提供的压缩包中的.py和.pyc文件复制到/tensorrtx/yolov5/文件夹中,如果直接用幻思压缩包中的工程则无需复制。
cd yolov5/
wget https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt
cp ~/tensorrtx/yolov5/gen_wts.py .
pip install numpy==1.20.3
python gen_wts.py -w yolov5s.pt -o yolov5s.wts
pip install numpy==1.23.0
此时会生成 'yolov5s.wts' 文件.
cd ~/tensorrtx/yolov5/
mkdir build
cd build
cp ~/yolov5/yolov5s.wts .
cmake .. # 如果使用幻思提供的tensorrtx包,最好先清空build文件夹再进行cmake ..
make
./yolov5_det -s yolov5s.wts yolov5s.engine s
pip install pycuda
pip install pyserial
cd ~/tensorrtx/yolov5
sudo chmod 777 /dev/ttyTHS0
将Jetson电源调到MAXN,运行下面
python yolov5_det_trt.py
全部工程自动运行
配置串口可执行权限:
用如下指令把权限配置文件复制到目录/etc/udev/rules.d/中
sudo cp 70-ttyusb.rules /etc/udev/rules.d/
重启电脑后生效
sh auto_ap.sh
开机自启动
- 配置ubuntu系统 auto login
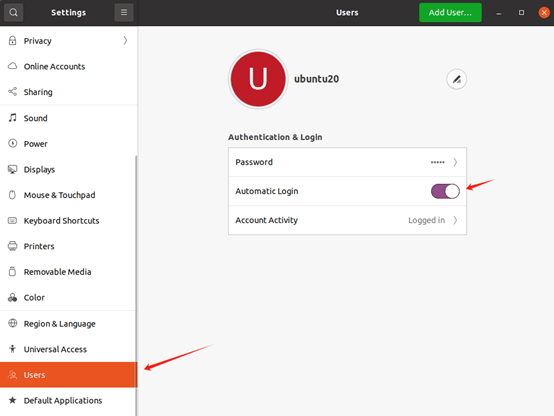
(2)配置自启动文件 auto_ap.sh
注意文件中的工程路径是否与自己的一致,不一致的自己修改一下。
(3)终端输入sh auto_ap.sh
检测slam工程是否在一分钟内正常启动
(4)配置auto_ap.sh开机自动运行

打开Startup Application

点击add
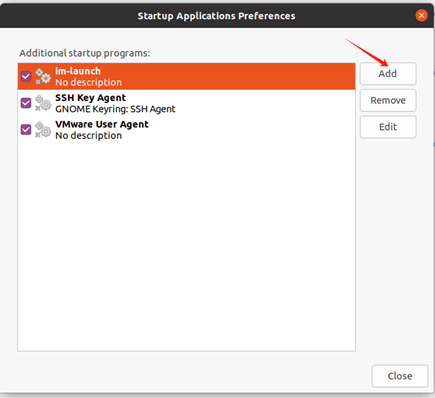
先填个Name,再在Command处添加sh /home/nv/auto_ap.sh。
此时已完成开机自启动配置
(5)推荐把Jetson NX的功率设置为MAXN
重启系统验证一下吧!看看yolo界面有没有在开机1分钟内正常运行。
第二章 JetsonNX视频流传输
概述
本节教程你将学会如何将JetsonNX上的CSI摄像头数据以TCP协议发送到PC端。
文件总览
TcpNoDelay_transtream_NX.py
TcpNoDelay_recvstream_PC.py
环境配置
确保JetsonNX环境已经按照“JetsonNX基础环境搭建”配置完毕
PC端环境配置:
python环境:3.10
安装opencv以及对应版本的numpy
pip install opencv-contrib-python==4.6.0.66
pip install numpy==1.24.0
运行程序
JetsonNX端
python3 TcpNoDelay_transtream_NX.py
![]()
PC端
python TcpNoDelay_recvstream_PC.py
![]()
代码讲解
JetsonNX端代码
- 导入库文件并定义全局参数
- TCP_IP设置为0.0.0.0代表监听外来所有ip
import socket
import cv2
import numpy as np
# 配置 {#配置 }
TCP_IP = '0.0.0.0'
TCP_PORT = 5005
- 套接字通信对象的创建和使用GStreamer管道配置打开摄像头
- 接下来是一个名为gstreamer_pipeline的函数,用于生成GStreamer管道字符串。这个函数允许用户根据参数配置摄像头的输入输出流。
- 最后就是使用gstreamer_pipeline函数的输出作为摄像头数据传入cap中。
# 实例化套接字通信对象 {#实例化套接字通信对象 }
def gstreamer_pipeline(
sensor_id=0,
capture_width=1920,
capture_height=1080,
display_width=960,
display_height=540,
framerate=30,
flip_method=0,
):
return (
"nvarguscamerasrc sensor-id=%d ! "
"video/x-raw(memory:NVMM), width=(int)%d, height=(int)%d, framerate=(fraction)%d/1 ! "
"nvvidconv flip-method=%d ! "
"video/x-raw, width=(int)%d, height=(int)%d, format=(string)BGRx ! "
"videoconvert ! "
"video/x-raw, format=(string)BGR ! appsink"
% (
sensor_id,
capture_width,
capture_height,
framerate,
flip_method,
display_width,
display_height,
)
)
# 初始化摄像头 {#初始化摄像头 }
cap = cv2.VideoCapture(gstreamer_pipeline(flip_method=2), cv2.CAP_GSTREAMER)
if not cap.isOpened():
print("无法打开摄像头,尝试使用默认摄像头设备")
cap = cv2.VideoCapture(0)
# 创建服务器套接字 {#创建服务器套接字 }
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind((TCP_IP, TCP_PORT))
sock.listen(1)
print(f"服务器已启动,监听 {TCP_IP}:{TCP_PORT}")
- 使用一个死循环不断读取cap摄像头对象中的数据,图像数据传入frame中再通过编码,字节转化,最终TCP发送。
try:
while True:
print("等待客户端连接...")
conn, addr = sock.accept()
print(f"客户端已连接:{addr}")
conn.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)
try:
while True:
ret, frame = cap.read()
if not ret:
print("无法读取摄像头画面")
break
# 编码为JPEG
encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), 70]
result, img_encoded = cv2.imencode('.jpg', frame, encode_param)
if not result:
continue
data = img_encoded.tobytes()
# 发送图像大小(4字节)
conn.sendall(len(data).to_bytes(4, 'big'))
# 发送图像数据
conn.sendall(data)
# 显示本地画面(可选)
cv2.imshow('Sending Image', frame)
if cv2.waitKey(1) == 27: # 按 ESC 退出
raise KeyboardInterrupt
except (BrokenPipeError, ConnectionResetError) as e:
print(f"[错误] 客户端断开连接: {e}")
finally:
conn.close()
print("客户端连接已关闭,等待新连接...")
except KeyboardInterrupt:
print("服务器正在关闭...")
finally:
cap.release()
cv2.destroyAllWindows()
sock.close()
print("所有资源已释放")
PC端代码
- 导入库文件
import cv2
import numpy as np
import subprocess
from multiprocessing import Array
- 使用ffplay来接受视频流并使用cv2.imshow来播放(ffplay是ffmpeg提供的方法,如何下载自行查找)
- 创建共享内存,使用ffplay接收流数据,使用自定义video_display数据来展示画面
def video_display(ffmpeg_command, frame_array, W_img, H_img):
process = subprocess.Popen(ffmpeg_command, stdout=subprocess.PIPE)
while True:
raw_frame = process.stdout.read(W_img * H_img * 3) # RGB 3 channels
if not raw_frame:
break
# 将帧复制到共享内存中
frame = np.frombuffer(raw_frame, dtype=np.uint8).reshape(H_img, W_img, 3)
np.copyto(np.frombuffer(frame_array.get_obj(), dtype=np.uint8).reshape(H_img, W_img, 3), frame)
# 显示帧
cv2.imshow('Real-Time Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
process.terminate()
if __name__ == '__main__':
W_img = 640
H_img = 480
shared_frame = Array('B', W_img * H_img * 3) # RGB 3通道,大小为像素数 × 3
ffmpeg_command = [
'ffplay',
'-i', 'tcp://192.168.0.112:5005', # 这里的地址要使用JetsonNX的地址,需要自行替换。
'-vf', 'setpts=N/30',
'-fflags', 'nobuffer',
'-flags', 'low_delay',
'-framedrop'
]
video_display(ffmpeg_command, shared_frame, W_img, H_img)
将视频流传输引入yolov5检测程序当中
把下面文件复制到tensorrtx/yolov5/文件夹中替换yolov5_det_trt.py文件
替换之后可以实现我们在运行第一章yolo识别程序的同时,将视频流传输到PC端
下面说明一下我们更改/增添的python代码
我们需要重新定义一个线程去监听端口等待客户端连接,因此需要引入多线程的库,将下面库放在yolov5_det_trt.py的导入库文件部分
import queue
import socket
import multiprocessing as mp
TCP_IP = '0.0.0.0'
TCP_PORT = 5005
然后将我们的线程类插入到yolov5_det_trt.py文件当中,可以加在程序主入口的上面部分
class TranstreamThread(threading.Thread):
def __init__(self, TCP_IP, TCP_PORT):
super().__init__()
self.TCP_IP = TCP_IP
self.TCP_PORT = TCP_PORT
self.sock = None
self.conn = None
self.addr = None
self.running = True
self.connected = False
self.queue = queue.Queue()
def run(self):
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 允许端口重用
self.sock.bind((self.TCP_IP, self.TCP_PORT))
self.sock.listen(1)
print(f"服务器已启动,监听 {self.TCP_IP}:{self.TCP_PORT}")
while self.running:
print("等待客户端连接...")
try:
self.conn, self.addr = self.sock.accept() # 每次 accept 一个新的客户端
print(f"客户端已连接:{self.addr}")
self.connected = True
# 设置 TCP_NODELAY
self.conn.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)
# 处理当前客户端通信
while self.running and self.connected:
try:
frame = self.queue.get(timeout=1) # 等待图像帧
self._send_frame(frame)
except queue.Empty:
continue
except socket.error as e:
print(f"accept() 出错:{e}")
self.connected = False
continue
def _send_frame(self, frame):
try:
size_data = len(frame).to_bytes(4, 'big')
self.conn.sendall(size_data)
self.conn.sendall(frame)
except (socket.error, BrokenPipeError) as e:
print(f"客户端断开连接:{e}")
self.connected = False # 客户端断开后标记为未连接
self._close_connection()
def send_frame(self, frame):
if self.connected:
self.queue.put(frame)
return True
return False
def _close_connection(self):
if self.conn:
try:
self.conn.close()
except:
pass
self.conn = None
def stop(self):
self.running = False
self.connected = False
self._close_connection()
if self.sock:
self.sock.close()
if __name__ == "__main__":
###
接着我们在程序入口创建线程类的实例并且运行
# create a new thread to do warm_up {#create-a-new-thread-to-do-warm_up }
thread1 = inferThread(yolov5_wrapper)
thread1.start()
thread1.join()
thread2 = TranstreamThread(TCP_IP, TCP_PORT) # 这句是我们要加入的
thread2.start() # 这句是我们要加入的
print('data link is starting...\n')
drone_thread=threading.Thread(target=dl.drone)
最后,由于多了一个线程计算,主线程中我们需要更快的处理速度,将cv2.imshow函数后面的waitkey(10)改成waitkey(1),再中间加入我们的发送图像帧的代码。
if cv2.getWindowProperty(window_title, cv2.WND_PROP_AUTOSIZE) >= 0:
cv2.imshow(window_title, img)
# 推理完图像后,编码为 JPEG 并发送
encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), 70]
result, img_encoded = cv2.imencode('.jpg', frame, encode_param)
data = img_encoded.tobytes()
thread2.send_frame(data) # 通过队列异步发送
else:
break
keyCode = cv2.waitKey(1) & 0xFF
# Stop the program on the ESC key or 'q' {#stop-the-program-on-the-esc-key-or-q }
if keyCode == 27 or keyCode == ord('q'):
break
第三章 JetsonNX从训练到运行
概述
本节教程将会教会你使用yolov5开源算法。过程中你需要经过下面几个步骤
拍摄训练集-->训练集标注-->模型训练-->模型部署-->算法应用
所使用到的工具:
- 模型训练载体,可以是你的个人PC(要求有NVIDIA显卡)或者云端算力平台(魔塔社区每周有一定的免费的GPU算力)
- 我们公司搭载了机载电脑的无人机产品。
- 显示屏,键盘,鼠标等外设。
本教程实验平台:
- windows11(python3.10.18)
- NVIDIA GeForce RTX 5060 Laptop GPU
- 幻思创新FanciSwarm 机载视觉智能套件
文件总览
yolov5.zip
tackpic.zip
Labelimg-中文编译版.exe
- JetsonNX端的文件包(在资料包中下载)
20.04-yolo
├─ 70-ttyusb.rules
├─ auto_ap.sh
├─ datalink_serial.py
├─ mavcrc.py
├─ mavcrc.pyc
├─ mavlink.py
├─ mavlink.pyc
├─ opencv-4.6.0.zip
├─ opencv_contrib-4.6.0.zip
├─ tensorrtx.zip
├─ torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
├─ vision-release-0.16.zip
├─ yolov5.zip
├─ yolov5_det_trt.py
└─ tensorrtx
└─ yolov5
├─ CMakeLists.txt
├─ yolov5_det_trt.py
├─ __pycache__
│ ├─ datalink_serial.cpython-38.pyc
│ ├─ mavcrc.cpython-38.pyc
│ └─ mavlink.cpython-38.pyc
├─ src
│ ├─ calibrator.cpp
│ ├─ calibrator.h
│ ├─ config.h
└─ build
├─ CMakeCache.txt
├─ cmake_install.cmake
├─ libmyplugins.so
├─ Makefile
├─ yolov5s.engine
├─ yolov5s.wts
├─ yolov5_cls
├─ yolov5_det
├─ yolov5_seg
├─ _bus.jpg
├─ _zidane.jpg
└─ CMakeFiles
convert2wts
├─ gen_wts.py
└─ unpickle.py
个人PC上安装yolov5依赖
- 找到一个没有中文路径的文件夹,使用下面命令拉取yolov5仓库,并进入yolov5文件夹(没有安装git的请自行安装:https://git-scm.com/downloads)
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install ultralytics
pip install -r requirements.txt
- (可选步骤,个人PC没有GPU的用户可直接使用CPU)在powershell中执行下面命令查看自己的CUDA版本
nvidia-smi
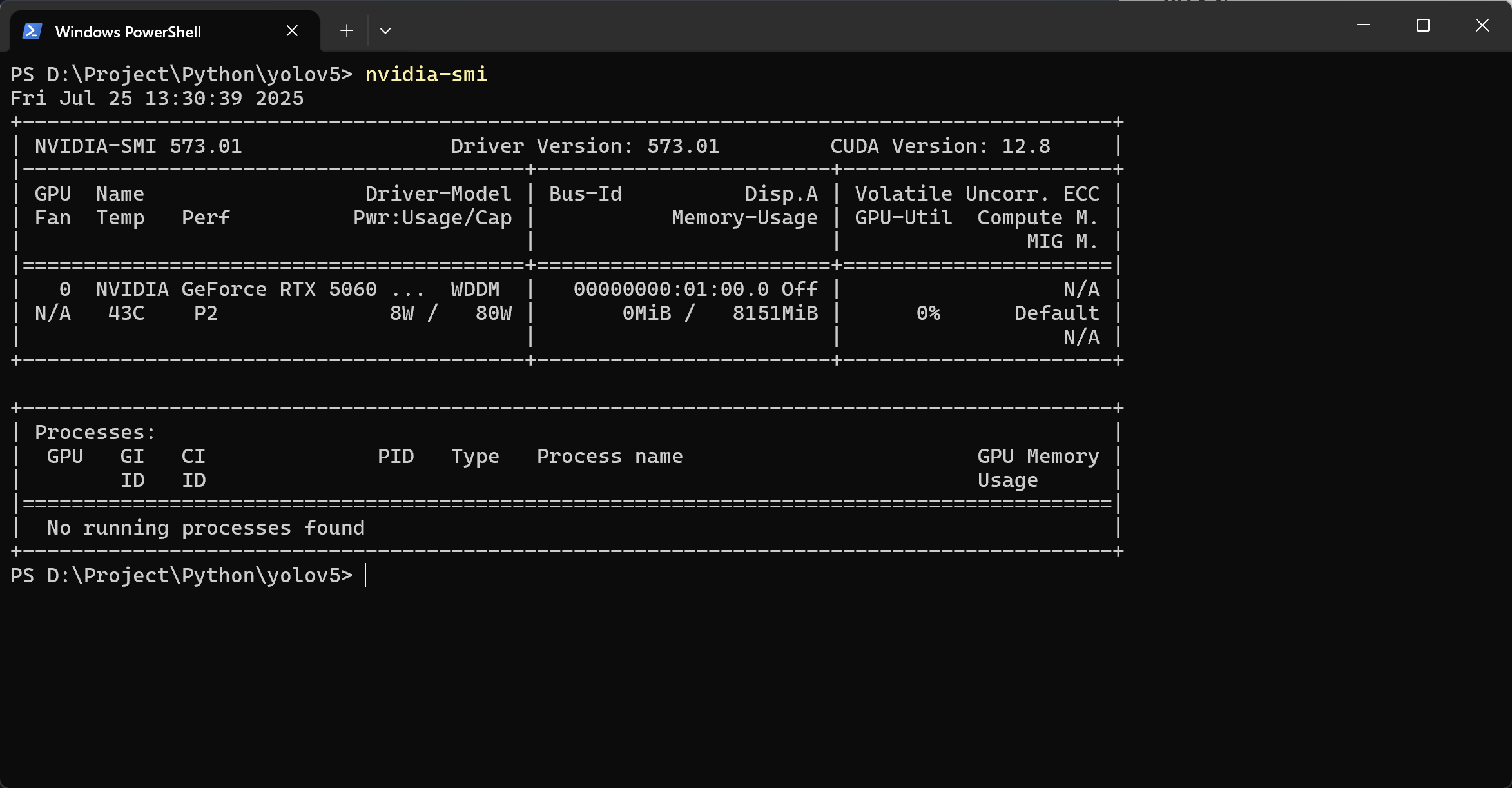
可以看到我的CUDA版本是12.8,那么下面的网址选择cu128,其他版本的CUDA版本要自行更换
pip uninstall torch torchvision # 卸载cpu版本的torch和torchvision
pip install torch torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cu128 # 安装GPU版本的torch和torchvision
测试环境是否配置正确:
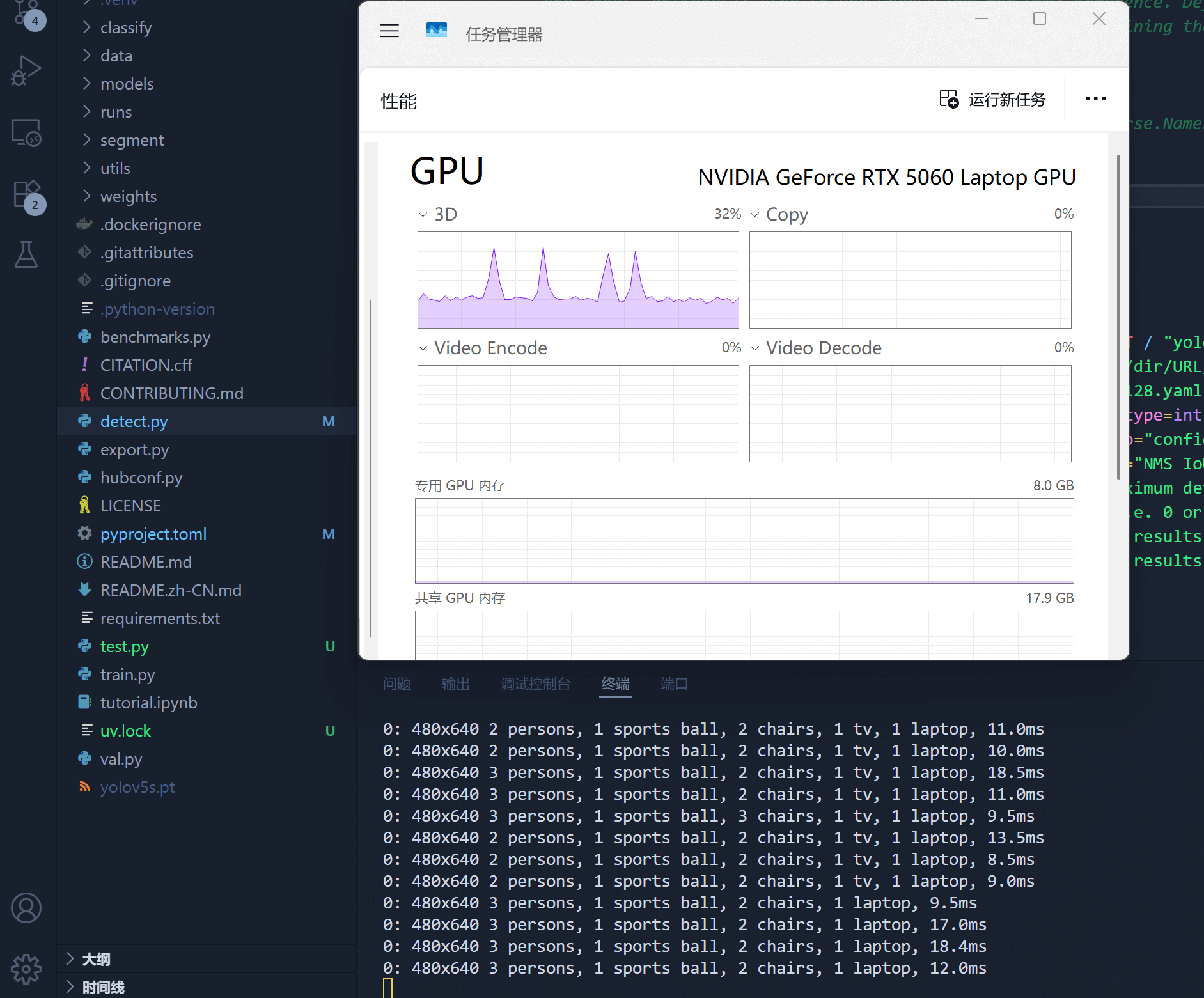
python detect.py --weights yolov5s.pt --source 0- detect.py 为识别脚本,使用yolov5s模型,识别来源为摄像头,即是PC电脑插的第一个摄像头。
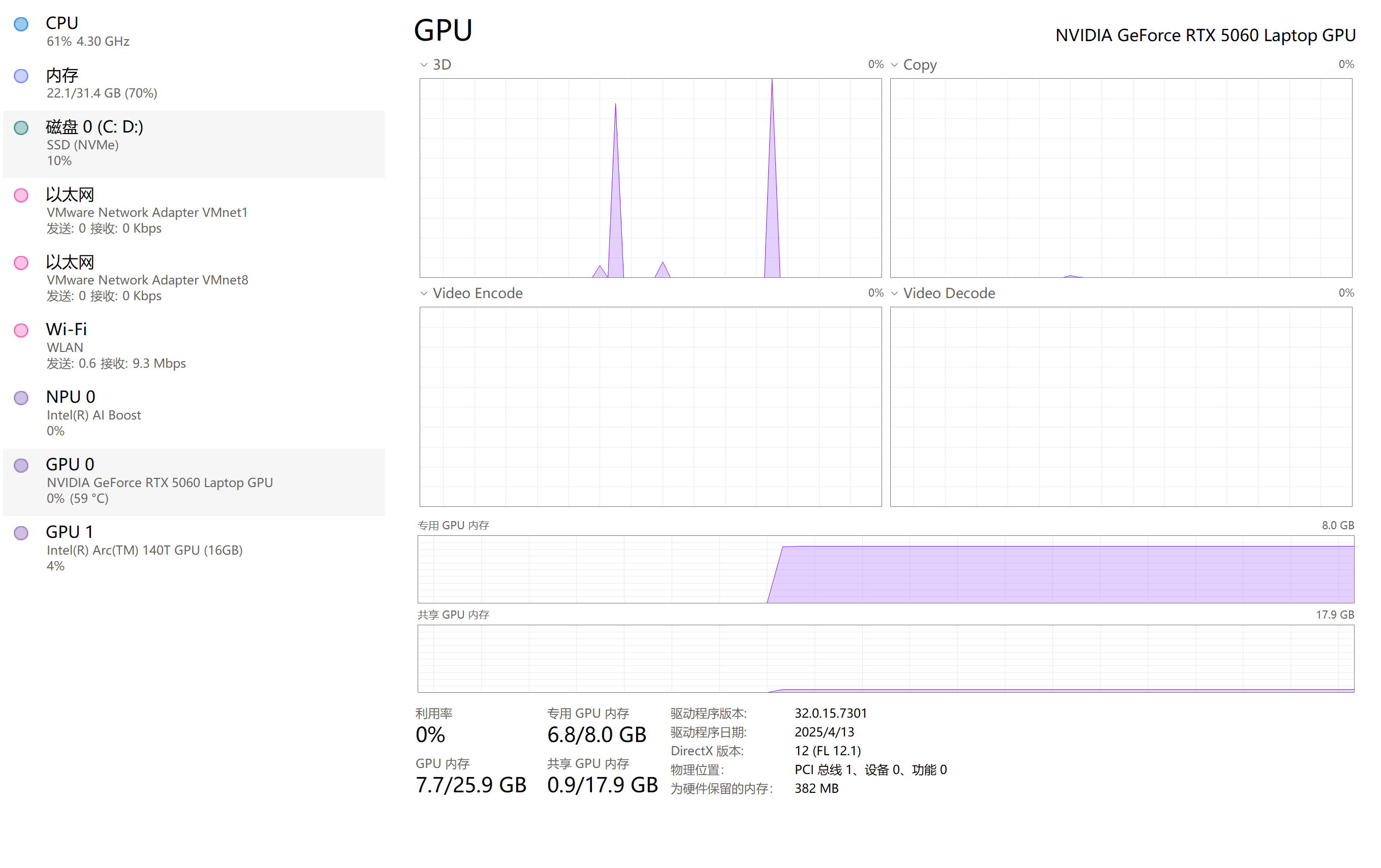
- 正常执行程序的情况下,打开任务管理器,若GPU监视窗口明显有占用变化,则为GPU调用成功。
使用JetsonNX摄像头拍摄训练集并标注
- 将JetsonNX连接好显示器,键盘,鼠标,最后插上电源线,确保之前已经按照前两张教程配置好环境。
- 将文件包takepic.zip中的takepic.py和images文件夹复制到Desktop目录下面,运行下面命令(如遇路径问题自行更正),按下之后"s"键保存当前帧图片。
python3 takepic.py
- 拍摄好图片之后将images文件夹做好备份
- 使用我们提供的labelimg.exe程序来进行数据集标注
- 打开Labelimg程序首先转换数据集格式为YOLO

- 然后设置自动保存
- 最后打开图片目录和更改标签存放目录
- 等到所有图片都划分完毕训练集即可退出程序

- Labelimg快捷键
- “w” -- 框选
- "a" -- 上一张图片
- "d" -- 下一张图片
- 使用我们给的huafen.py去划分数据集,文件第5行可以根据自己要求修改train,val的比例。
def split_dataset(image_folder, txt_folder, output_images_path, output_labels_path, split_ratio=(0.7, 0.3)):
使用前请自行更改路径变量
image_folder_path = "D:\Data\images_ready2train\images"
txt_folder_path = "D:\Data\images_ready2train\labels"
output_images_path = "D:\Data\images_ready2train\datasets\images"
output_labels_path = "D:\Data\images_ready2train\datasets\labels"
训练模型
- 将划分完的datasets放到yolov5文件夹下面,为datasets编写yaml文档,在yolov5的data文件夹下面创建drone.yaml文件仿照coco128.yaml填写,注意这里的path是相对于train.py的路径而不是yaml的路径。
path: ./datasets/
train: images/train
val: images/val
# Classes {#classes }
names:
0: drone
- 更改train.py的参数
- --weights 训练的预训练权重,官方有l,m,n,s,x大部分选用s
- --cfg和权重对应的配置文件
- --data 数据集yaml文件,就是我们上一步的drone.yaml
- --epochs 训练轮数,一般设置100-300轮就能让误差曲线下降到最低点
- --batchsize 训练批次,一般设置为8,或者2的次幂,根据电脑显存来,太大会报异常,可以先设置小batchsize,观察GPU显存占用情况再调整
- --imgsz 设置网络模型图片大小,无论你传入多大,yolo都会resize成这个大小。
- --device 可以选用cpu GPU等训练设备,本教程使用GPU
- --workers cpu线程数量,根据cpu核心来判断,电脑性能不行的话就不要高于5。
- 最终附上本教程的参数详情
parser.add_argument("--weights", type=str, default=ROOT / "yolov5s.pt", help="initial weights path")
parser.add_argument("--cfg", type=str, default="", help="model.yaml path")
parser.add_argument("--data", type=str, default=ROOT / "data/drone.yaml", help="dataset.yaml path")
parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-low.yaml", help="hyperparameters path")
parser.add_argument("--epochs", type=int, default=100, help="total training epochs")
parser.add_argument("--batch-size", type=int, default=-1, help="total batch size for all GPUs, -1 for autobatch")
parser.add_argument("--imgsz", "--img", "--img-size", type=int, default=640, help="train, val image size (pixels)")
parser.add_argument("--rect", action="store_true", help="rectangular training")
parser.add_argument("--resume", nargs="?", const=True, default=False, help="resume most recent training")
parser.add_argument("--nosave", action="store_true", help="only save final checkpoint")
parser.add_argument("--noval", action="store_true", help="only validate final epoch")
parser.add_argument("--noautoanchor", action="store_true", help="disable AutoAnchor")
parser.add_argument("--noplots", action="store_true", help="save no plot files")
parser.add_argument("--evolve", type=int, nargs="?", const=300, help="evolve hyperparameters for x generations")
parser.add_argument(
"--evolve_population", type=str, default=ROOT / "data/hyps", help="location for loading population"
)
parser.add_argument("--resume_evolve", type=str, default=None, help="resume evolve from last generation")
parser.add_argument("--bucket", type=str, default="", help="gsutil bucket")
parser.add_argument("--cache", type=str, nargs="?", const="ram", help="image --cache ram/disk")
parser.add_argument("--image-weights", action="store_true", help="use weighted image selection for training")
parser.add_argument("--device", default="0", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")
parser.add_argument("--multi-scale", action="store_true", help="vary img-size +/- 50%%")
parser.add_argument("--single-cls", action="store_true", help="train multi-class data as single-class")
parser.add_argument("--optimizer", type=str, choices=["SGD", "Adam", "AdamW"], default="SGD", help="optimizer")
parser.add_argument("--sync-bn", action="store_true", help="use SyncBatchNorm, only available in DDP mode")
parser.add_argument("--workers", type=int, default=2, help="max dataloader workers (per RANK in DDP mode)")
parser.add_argument("--project", default=ROOT / "runs/train", help="save to project/name")
parser.add_argument("--name", default="exp", help="save to project/name")
parser.add_argument("--exist-ok", action="store_true", help="existing project/name ok, do not increment")
parser.add_argument("--quad", action="store_true", help="quad dataloader")
parser.add_argument("--cos-lr", action="store_true", help="cosine LR scheduler")
parser.add_argument("--label-smoothing", type=float, default=0.0, help="Label smoothing epsilon")
parser.add_argument("--patience", type=int, default=100, help="EarlyStopping patience (epochs without improvement)")
parser.add_argument("--freeze", nargs="+", type=int, default=[0], help="Freeze layers: backbone=10, first3=0 1 2")
parser.add_argument("--save-period", type=int, default=-1, help="Save checkpoint every x epochs (disabled if < 1)")
parser.add_argument("--seed", type=int, default=0, help="Global training seed")
parser.add_argument("--local_rank", type=int, default=-1, help="Automatic DDP Multi-GPU argument, do not modify")
# Logger arguments {#logger-arguments }
parser.add_argument("--entity", default=None, help="Entity")
parser.add_argument("--upload_dataset", nargs="?", const=True, default=False, help='Upload data, "val" option')
parser.add_argument("--bbox_interval", type=int, default=-1, help="Set bounding-box image logging interval")
parser.add_argument("--artifact_alias", type=str, default="latest", help="Version of dataset artifact to use")
# NDJSON logging {#ndjson-logging }
parser.add_argument("--ndjson-console", action="store_true", help="Log ndjson to console")
parser.add_argument("--ndjson-file", action="store_true", help="Log ndjson to file")
最后将run文件夹下的best.pt取出,可以使用detect.py检查下训练效果是否符合预期,再上传到JetsonNX端进行模型转换。
JetsonNX端的模型转换
- 将准备好的模型放到JetsonNX端的yolo文件夹下面,使用我们提供的convert2wts文件包中的gen_wts.py 和 unpickle.py放到 yolo文件夹,来进行py模型到wts模型的转换
- 在yolo文件夹的终端执行下面命令,生成wts模型
pip install numpy==1.20.3
python gen_wts.py -w ./drone.pt -o ./drone.wts
# python gen_wts.py -w [pt模型路径] -o [wts模型名称] {#python-gen_wtspy--w-pt模型路径--o-wts模型名称 }
pip install numpy==1.23.0
- 在tensorrtx/yolov5/src/的文件夹下的config.h文件中
constexpr static int kNumClass = 1; // 更改成训练模型的类别数量
更改为你所训练的模型的类别数量
4. 在tensorrtx/yolov5文件夹下面创建build文件夹(如果使用我们提供的tensorrtx压缩包,那需要先把build文件夹下文件删除干净)
mkdir build
cd ./build
cmake ..
make
- 生成了可执行文件之后进入build文件夹,再把之前生成的wts模型文件放到build文件夹中,最后执行下面命令。
./yolov5_det -s drone.wts drone.engine s
# ./yolov5_det -s [wts模型文件路径] [engine模型名称] [s/m/l,根据训练时候的预训练权重] {#yolov5_det--s-wts模型文件路径-engine模型名称-sml根据训练时候的预训练权重 }
JetsonNX端模型使用
- 将上一步生成的engine模型文件放在tensorrtx的yolov5文件夹中,更改yolov5_det_trt.py如下
- 17行
W_real = 0.12 # target实际宽度,米
H_real = 0.12 # target实际高度,米
- 588行
engine_file_path = "./build/drone.engine"
- 599行
categories = ["drone"]
- 235行
if result_scores[j] > 0.5 and categories[int(result_classid[j])] == 'drone'
# 你要识别的类别名 {#你要识别的类别名 }
如果不需要单个类别检测则可以下面修改
if result_scores[j] > 0.5
第四章 JetsonNX识别追踪Aruco码
项目概述
本节教程将会教会你如何使用FanciSwarm单目视觉智能套件实现Aruco码的前视视角的识别追踪和俯视视角的识别降落。
文件总览
Aruco_dectction_NX
├─ calibration_data.npz
├─ datalink_serial.py
├─ aruco_dectction_nx.py
├─ mavcrc.py
├─ mavcrc.pyc
├─ mavlink.py
├─ mavlink.pyc
├─ biaoding.py
├─ __pycache__
│ ├─ datalink_serial.cpython-38.pyc
│ ├─ mavcrc.cpython-36.pyc
│ ├─ mavcrc.cpython-38.pyc
│ ├─ mavlink.cpython-36.pyc
│ └─ mavlink.cpython-38.pyc
└─ .vscode
└─ settings.json
相机标定参数的生成
我们在使用aruco码检测程序的时候需要用到单目测距,因此需要提前获取相机标定参数
首先去网上下载标定专用棋盘格
https://github.com/opencv/opencv/blob/master/doc/pattern.png
{kind=link}
接着我们使用第三章的文件takepic.py去进行图像采集,采集过程中要确保下面要点
- 尽量从不同的角度、不同的距离拍摄棋盘格。
- 每张照片中的棋盘格应尽量占据较大的画面区域。
- 确保所有棋盘格点都清晰可见并没有因反光等原因模糊不清。
将拍摄好的图片保存在images文件夹下,放到我们的文件包中。
然后我们打开biaoding.py文件,修改下面图片存放路径(第17行)
images = glob.glob('images/*.jpg')
运行biaoding.py文件得到calibration_data.npz参数文件
Aruco码识别
我们修改文件包中的aruco_dectction_nx.py文件中你保存的参数路径(第11行)
with np.load('/home/nv/Desktop/Aruco/calibration_data.npz') as data:
camera_matrix = data['camera_matrix']
dist_coeffs = data['dist_coeffs']
修改开机自启动项
将我们工程包的aruco_ap.sh放到home/nv目录下
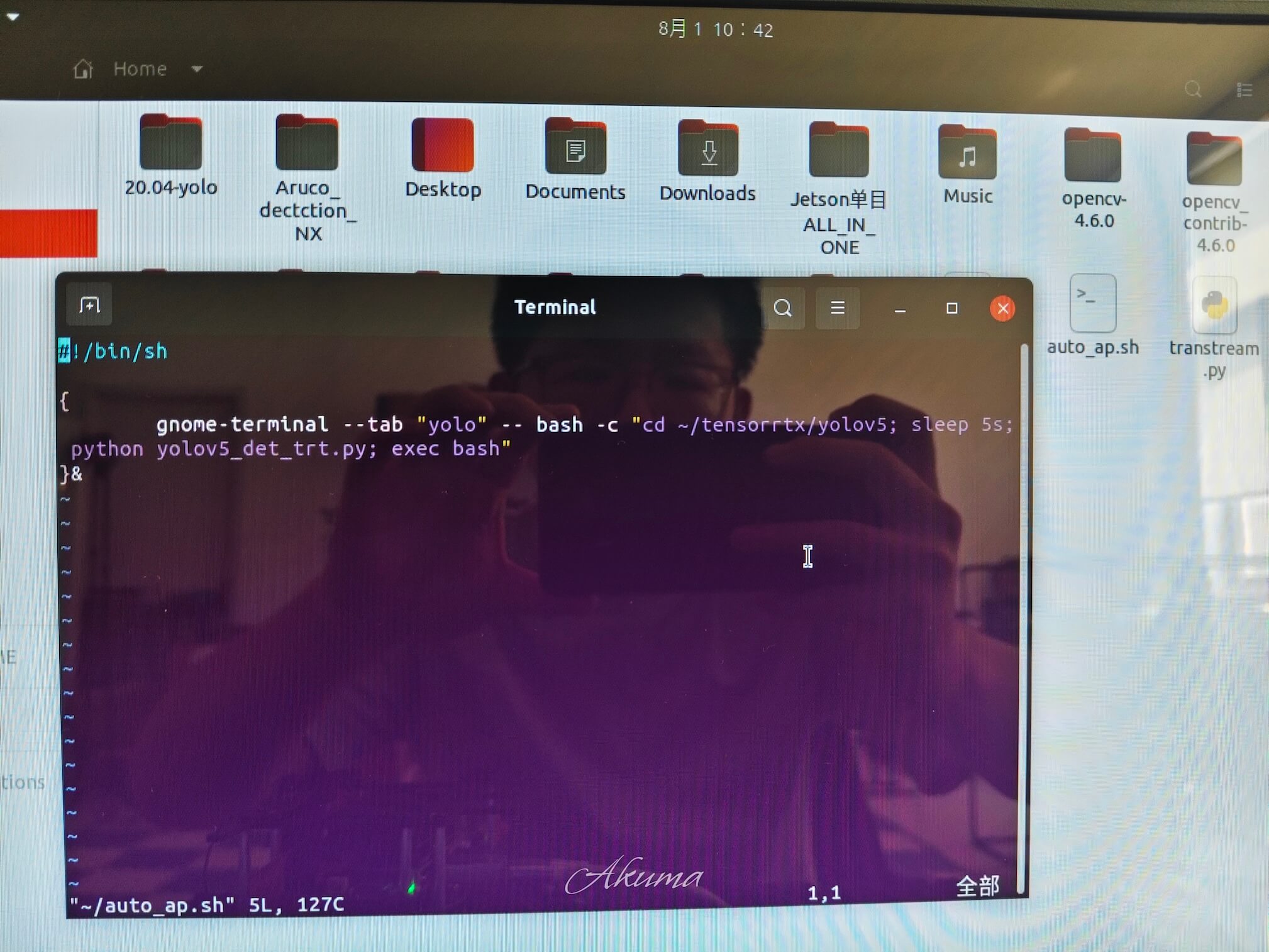
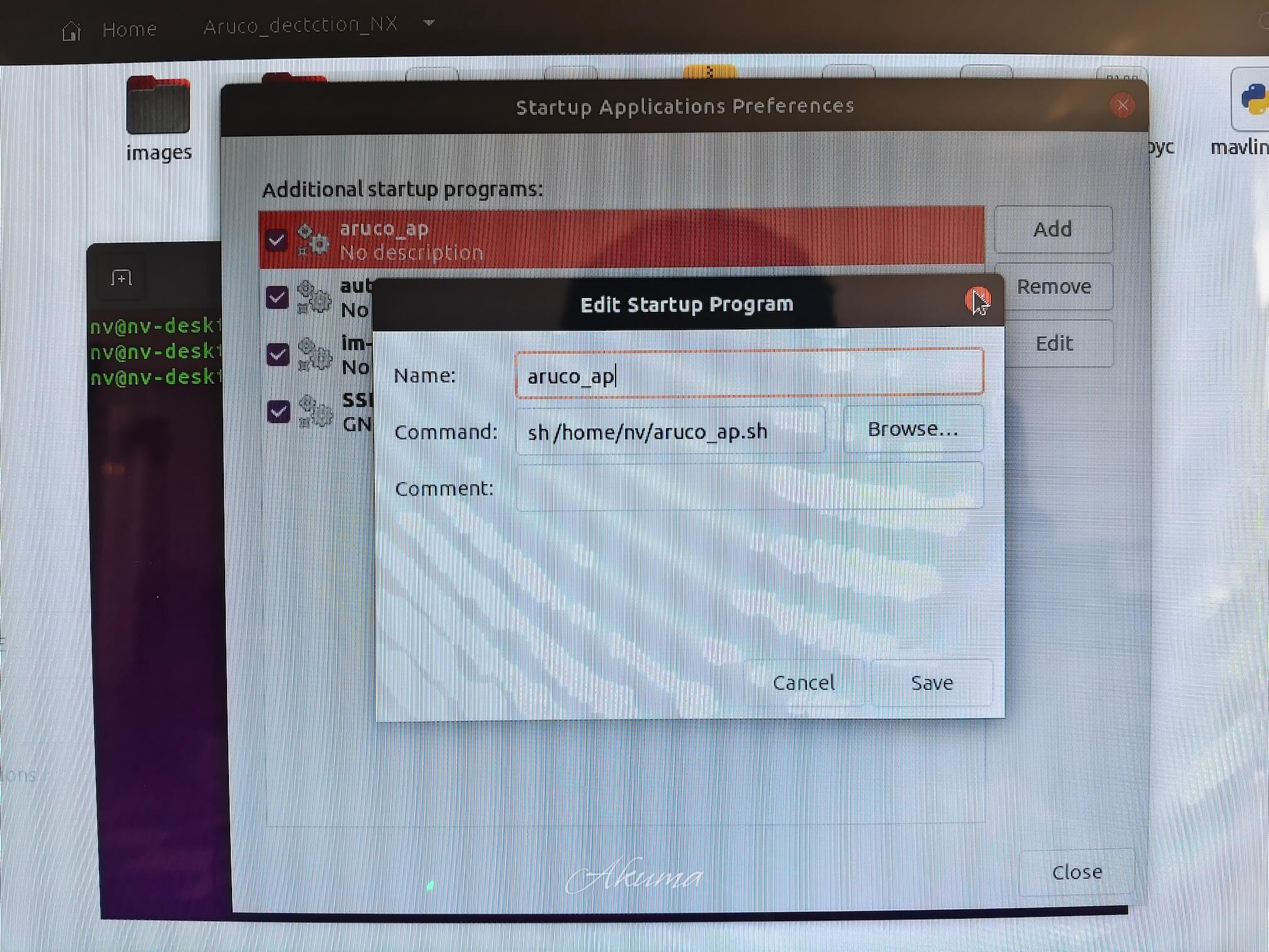
然后打开Startup Appcation修改启动脚本
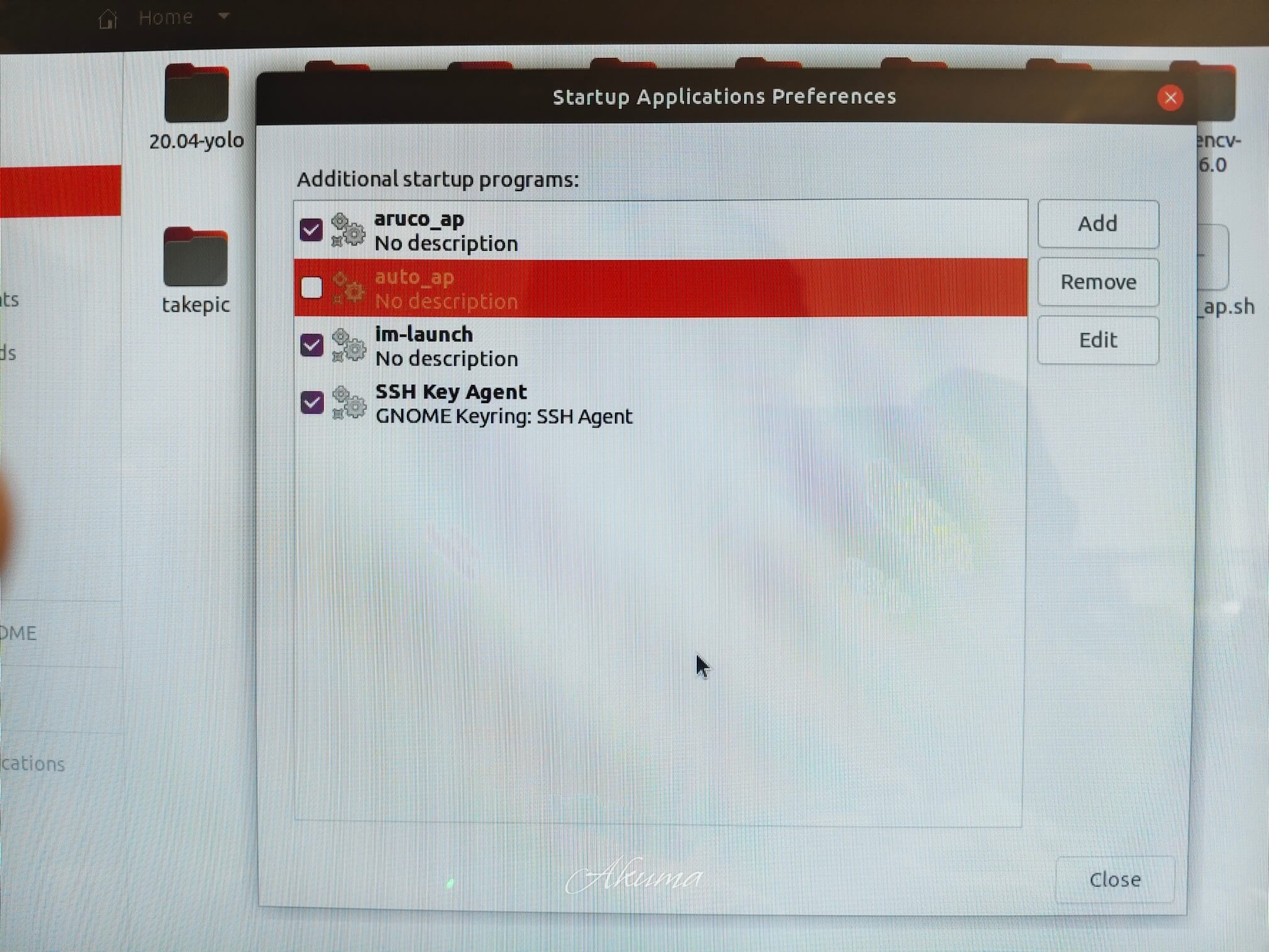
最后取消勾选之前的auto_ap.sh
前视视角的Aruco码识别追踪
前视视角安装的摄像头使用
文件包程序默认就是前视视角的识别追踪
前视视角更改为俯视视角Aruco码识别降落
俯视视角安装的摄像头使用
俯视视角只需要将set_pose函数更改为set_xy_pose如下所示
将
dl.set_pose(kp_x * dx_1, kp_y * dy_1, kp_alt * d_alt_1, kp_yaw * d_yaw)
更改为
dl.set_xy_pose(kp_alt * d_alt_1, kp_y * dy_1, 0)
第五章 识别追踪接入 ROS
注意:本节使用的 ROS 工程为 fcu_core_v2,不兼容 第一版的 fcu_core。
前面几章都是在 Ubuntu 20.04 自带的 Python 环境下直接与飞控通信并控制飞机。为了提高系统的可靠性与可扩展性,本章演示如何在 Jetson NX 上部署 ROS,并把 yolov5_det_trt.py 修改为 ROS 节点,从而实现通过 ROS 与上位机/飞控的协同控制与识别追踪。
接入 ROS 的好处:
- 统一由
fcu_core管理机载电脑(JetsonNX)与飞控之间的通信; - 可以复用并扩展我们维护的
fcu_core_v2功能,实现远程控制(如开启/关闭识别追踪)、更好的兼容性以及多节点协同。
ROS 环境搭建(机载电脑)
- 创建 ROS 工作空间
mkdir -p ~/ros_ws/src
cd ~/ros_ws/src
git clone https://github.com/fancinnov/fcu_core_v2.git
git clone https://github.com/fancinnov/quadrotor_msgs.git
- 配置 launch 参数(示例)
channel参数设为0表示使用串口通信;offboard参数设为true表示由机载电脑进行 offboard 控制。
示例片段:
<node pkg="fcu_core" type="fcu_bridge_001" name="fcu_bridge_001" output="screen">
<remap from="~odometry_001" to="Odometry"/>
<remap from="~imu_global_001" to="imu_global_001"/>
<remap from="~odom_global_001" to="odom_global_001"/>
<remap from="~path_global_001" to="path_global_001"/>
<remap from="~path_target_001" to="path_target_001"/>
<remap from="~goal_001" to="/move_base_simple/goal"/>
<remap from="~motion_001" to="motion_001"/>
<remap from="~command" to="/fcu_command/command"/>
<remap from="~mission_001" to="/fcu_mission/mission_001"/>
<param name="DRONE_IP" value="192.168.4.1" type="string"/>
<param name="USB_PORT" value="/dev/ttyTHS0" type="string"/>
<param name="channel" value="0"/>
<param name="offboard" value="true" type="bool"/>
<param name="use_uwb" value="false" type="bool"/>
<param name="set_goal" value="false" type="bool"/>
<param name="simple_target" value="true" type="bool"/>
<param name="odom_init_x" value="0.0"/> <!-- FLU 坐标系 -->
<param name="odom_init_y" value="0.0"/>
<param name="odom_init_z" value="0.0"/>
</node>
将识别追踪程序接入 ROS
本项目包含两类识别追踪程序:YOLO(目标检测)和 ArUco(Aruco 码检测)。
- YOLO 程序为
yolov5_det_trt.py; - ArUco 程序为
aruco_dectction_nx.py。
下面给出接入 ROS 的要点:
- 导入 ROS Python 包:
import rospy
from std_msgs.msg import Int16
from std_msgs.msg import Float32MultiArray
rospy 是 ROS 的 Python 客户端库;Int16 用于接收整数命令;Float32MultiArray 用于发布浮点数组形式的控制指令。
- 创建节点、订阅命令并创建发布者:
rospy.init_node('yolo_det_trt', anonymous=True)
command_sub = rospy.Subscriber('/fcu_command/command', Int16, command_callback)
mission_pub = rospy.Publisher('/mission_follow', Float32MultiArray, queue_size=100)
- 定义命令回调:
IsDetect = False
def command_callback(msg):
global IsDetect
if msg.data == 1001:
print("开始前视识别追踪")
IsDetect = True
elif msg.data == 1002:
print("开始俯视识别追踪")
# 根据需要在此设置为俯视模式
elif msg.data == 1003:
print("停止识别追踪")
IsDetect = False
- 创建控制指令发布函数
set_pose:
def set_pose(x, y, z, yaw):
msg = Float32MultiArray()
msg.data = [
yaw, 0,
x, y, z,
0, 0, 0, 0, 0, 0, 0]
mission_pub.publish(msg)
说明:这里使用长度为 11 的数组发布控制命令(按 fcu_core_v2 的接口格式)。
- 在主循环中根据
IsDetect控制是否执行识别追踪:
global IsDetect
if not IsDetect:
rospy.sleep(0.1)
continue # 跳出本次循环;在某些文件中(例如 yolo)改为 return,请参见替换文件
替换文件
为了方便,我们提供了已修改好的 ROS 版本脚本,直接替换对应位置即可:
- 将 yolov5_det_trt(ros).py 替换至
tensorrtx/yolov5/; - 将 aruco_dectction_nx(ros).py 替换至
Aruco_dectction_NX/。